# FunASR 安装使用
FunASR是一个基础语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。FunASR提供了便捷的脚本和教程,支持预训练好的模型的推理与微调。
github 地址: https://github.com/modelscope/FunASR (opens new window)
# docker 方式部署使用
# docker 安装
如果已经安装过 docker ,请忽略这一步。
curl -O https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/shell/install_docker.sh
sudo bash install_docker.sh
# 拉取 docker 镜像
FunASR 分离线模型和实时识别模型
funasr-runtime-sdk-cpu 离线模型
funasr-runtime-sdk-online-cpu 在线模型
离线模型参考链接: 离线模型 github 链接 (opens new window)
在线模型参考链接 : 在线模型 github 链接 (opens new window)
本文主要对在线模型安装及使用进行说明
sudo docker pull registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.13

# 启动镜像
# 创建一个存放模型的文件夹
mkdir -p /media/inspur/funasr-docker
# 启动镜像
sudo docker run -p 10098:10095 -it --privileged=true -v /media/inspur/funasr-docker:/workspace/models registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.13
# 启动服务端
docker启动之后,自动进入到 docker 容器里边,执行下面命令启动 funasr-wss-server 服务程序。
测试发现这种方式启动,一旦关闭终端,相应的服务也被停止了,如果想后台继续运行服务,参考下边的后台运行命令。
cd FunASR/runtime
nohup bash run_server_2pass.sh \
--certfile 0 \
--download-model-dir /workspace/models \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx \
--online-model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online-onnx \
--punc-dir damo/punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
--hotword /workspace/models/hotwords.txt > log.txt 2>&1 &
# 如果您想关闭ssl,增加参数:--certfile 0
# 如果您想使用SenseVoiceSmall模型、时间戳、nn热词模型进行部署,请设置--model-dir为对应模型:
# iic/SenseVoiceSmall-onnx
# damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx(时间戳)
# damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404-onnx(nn热词)
# 如果您想在服务端加载热词,请在宿主机文件./funasr-runtime-resources/models/hotwords.txt配置热词(docker映射地址为/workspace/models/hotwords.txt):
# 每行一个热词,格式(热词 权重):阿里巴巴 20(注:热词理论上无限制,但为了兼顾性能和效果,建议热词长度不超过10,个数不超过1k,权重1~100)
# SenseVoiceSmall-onnx识别结果中“<|zh|><|NEUTRAL|><|Speech|> ”分别为对应的语种、情感、事件信息
# 查看或关闭FunASR服务
# 查看 funasr-wss-server 对应的PID
# 在容器里边执行
ps -x | grep funasr-wss-server
kill -9 PID
# 在 docker 后台启动命令
sudo docker run -d \
--name funasr-online \
-p 10098:10095 \
--privileged=true \
-v /media/inspur/funasr-docker:/workspace/models \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.13 \
bash -c "
cd FunASR/runtime && \
bash run_server_2pass.sh \
--certfile 0 \
--download-model-dir /workspace/models \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx \
--online-model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online-onnx \
--punc-dir damo/punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
--hotword /workspace/models/hotwords.txt && \
tail -f /dev/null
"
# 源码方式启动
github 地址: https://github.com/modelscope/FunASR (opens new window)
# 安装依赖
为了不影响系统现有的 python 环境,使用 conda 创建一个 虚拟的环境。
请先安装 conda ,然后才能创建虚拟环境
# 创建 conda 环境
conda create -n funasr python=3.12.1 -y
# 激活环境
conda activate funasr
# 查看环境
conda env list
# Linux/Unix 平台编译
# 下载 onnxruntime
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/dep_libs/onnxruntime-linux-x64-1.14.0.tgz
tar -zxvf onnxruntime-linux-x64-1.14.0.tgz
# 下载 ffmpeg
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/dep_libs/ffmpeg-master-latest-linux64-gpl-shared.tar.xz
tar -xvf ffmpeg-master-latest-linux64-gpl-shared.tar.xz
# 安装依赖
# openblas
sudo apt-get install libopenblas-dev #ubuntu
# sudo yum -y install openblas-devel #centos
# openssl
apt-get install libssl-dev #ubuntu
# yum install openssl-devel #centos
# 编译 runtime
git clone https://github.com/alibaba-damo-academy/FunASR.git && cd FunASR/runtime/websocket
mkdir build && cd build
cmake -DCMAKE_BUILD_TYPE=release .. -DONNXRUNTIME_DIR=/path/to/onnxruntime-linux-x64-1.14.0 -DFFMPEG_DIR=/path/to/ffmpeg-master-latest-linux64-gpl-shared
make -j$(nproc)
# 启动服务
创建了一个启动脚本 start_funasr.sh 基于 conda
#!/bin/bash
# 实际conda 路径
CONDA_ROOT="/home/inspur/anaconda3"
# 虚拟环境名称
CONDA_ENV="funasr"
echo "Activate conda environment: $CONDA_ENV"
source "$CONDA_ROOT/etc/profile.d/conda.sh"
conda activate "$CONDA_ENV"
export PYTHONPATH=/workspace/FunASR:$PYTHONPATH
# 模型存放路径
export MS_MODEL_CACHE=/media/inspur/funasr-runtime-resources/models
echo "Starting FunASR server..."
nohup env MS_MODEL_CACHE=$MS_MODEL_CACHE bash run_server.sh \
--download-model-dir /media/inspur/funasr-runtime-resources/models \
--certfile 0 \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx \
--punc-dir damo/punc_ct-transformer_cn-en-common-vocab471067-large-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
> log.txt 2>&1 &
参数说明:
--download-model-dir 模型下载地址,通过设置model ID从Modelscope下载模型
--model-dir modelscope model ID 或者 本地模型路径
--vad-dir modelscope model ID 或者 本地模型路径
--punc-dir modelscope model ID 或者 本地模型路径
--lm-dir modelscope model ID 或者 本地模型路径
--itn-dir modelscope model ID 或者 本地模型路径
--port 服务端监听的端口号,默认为 10095
--decoder-thread-num 服务端线程池个数(支持的最大并发路数),
脚本会根据服务器线程数自动配置decoder-thread-num、io-thread-num
--io-thread-num 服务端启动的IO线程数
--model-thread-num 每路识别的内部线程数(控制ONNX模型的并行),默认为 1,
其中建议 decoder-thread-num*model-thread-num 等于总线程数
--certfile ssl的证书文件,默认为:../../../ssl_key/server.crt,如果需要关闭ssl,参数设置为0
--keyfile ssl的密钥文件,默认为:../../../ssl_key/server.key
--hotword 热词文件路径,每行一个热词,格式:热词 权重(例如:阿里巴巴 20),
如果客户端提供热词,则与客户端提供的热词合并一起使用,服务端热词全局生效,客户端热词只针对对应客户端生效。
第一次启动有点慢,需要下载模型文件
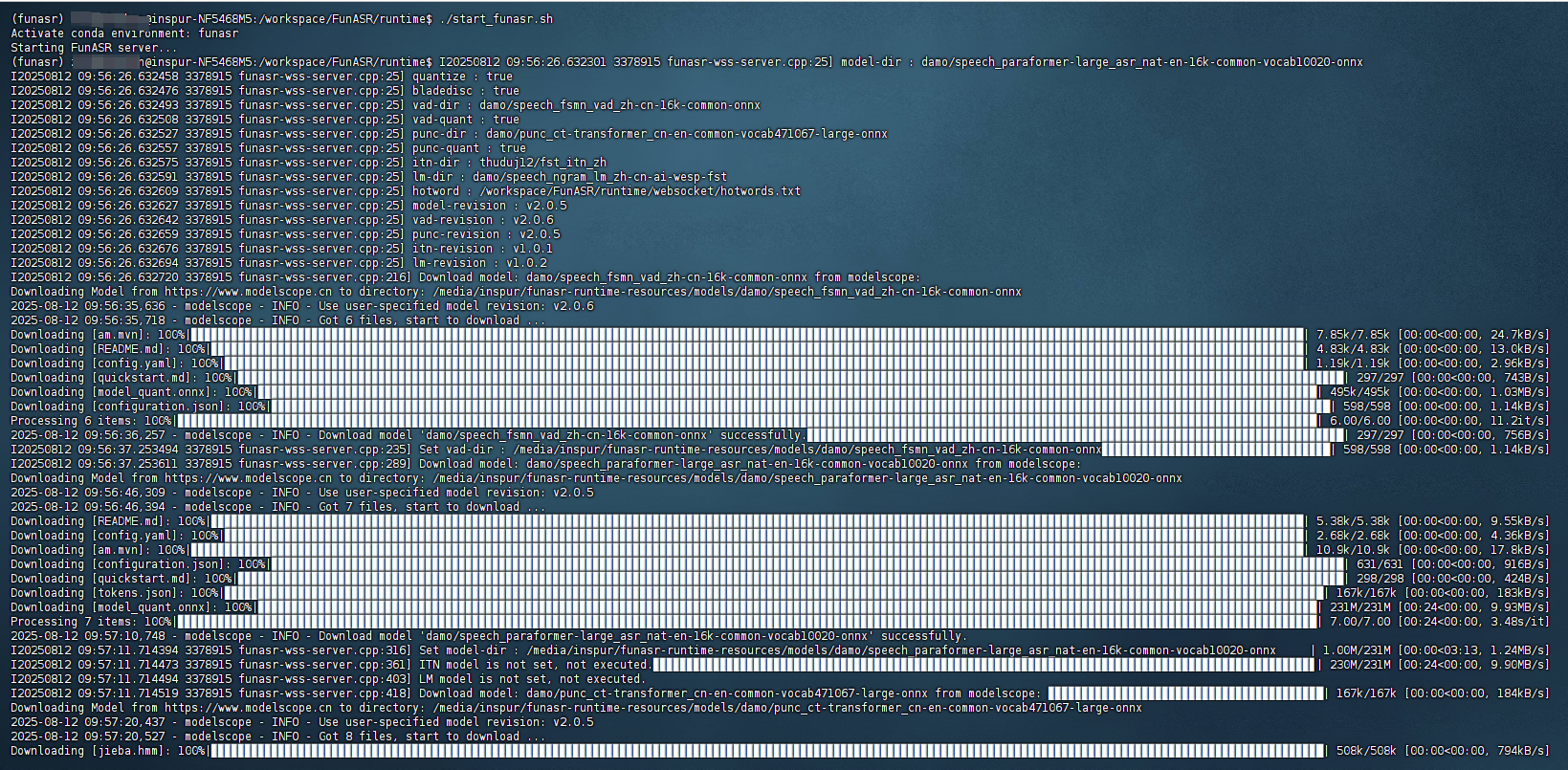
# 查看或关闭FunASR服务
# 查看 funasr-wss-server 对应的PID
ps -x | grep funasr-wss-server
kill -9 PID
# 测试
解压完里边有不同语言的测试示例
使用 html 页面打开,选择一个音频文件。
asr 服务器地址根据实际填写即可,这里使用的是 ws://192.168.5.179:10095

也可以实时语音识别

asr 模型模式:
- 2pass: (默认)实时语音识别,并且句尾采用离线模型进行纠错(准确度更高)
- online: 实时语音识别
- offline: 一句话识别
# websocket/grpc通信协议
websocket 发送参数说明,参考地址: https://github.com/modelscope/FunASR/blob/main/runtime/docs/websocket_protocol_zh.md (opens new window)
参考资料:
- https://harryai.cc/post/realtime-funasr/#%E6%95%88%E6%9E%9C%E5%B1%95%E7%A4%BA
- https://www.cnblogs.com/fengmian13wl/p/18120250
- https://github.com/modelscope/FunASR/blob/main/runtime/docs/SDK_advanced_guide_offline_gpu_zh.md#%E6%9C%8D%E5%8A%A1%E7%AB%AF%E7%94%A8%E6%B3%95%E8%AF%A6%E8%A7%A3
- https://harryai.cc/post/audio-notes/