# ollama 安装使用
ollama 是一个基于 Go 语言开发的简单易用的本地大语言模型运行框架。可以将其类比为 docker,有了 ollama 可以很方便的部署本地模型,无需对模型进行繁琐配置。
ollama 支持 Windows、Mac、Linux,本文以 Linux 为例
# 下载 ollama
从 ollama 官网获取安装命令
项目地址: https://ollama.com/ (opens new window)
复制安装命令 curl -fsSL https://ollama.com/install.sh | sh 并执行,然后会自动下载安装文件。

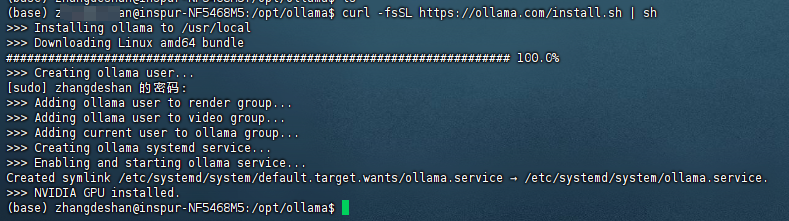
下载完成会自动创建用户及启动服务
注意: ollama.service 的位置,后边修改 ip 设置会用到
系统服务配置路径
/etc/systemd/system/ollama.service
# ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
Environment="CUDA_VISIBLE_DEVICES=1" # ⭐ 强制用 GPU 1
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/home/zh/.local/bin:/opt/docker20/bin:/home/zh/Ascend/ascend-toolkit/6.10.t06spc003b020/toolkit/bin:/home/zh/Ascend/ascend-toolkit/6.10.t06spc003b020/atc/bin:/home/inspur/anaconda3/bin:/home/inspur/anaconda3/condabin:/opt/linux/x86-arm/arm-v01c02-linux-musleabi-gcc/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/usr/local/cuda-12.4/bin:/usr/local/TensorRT-8.6.1.6/bin"
[Install]
WantedBy=default.target
# 设置模型存储路径
默认情况下模型文件的路径
- macOS:
~/.ollama/models - Linux:
/usr/share/ollama/.ollama/models - Windows:
C:\Users\<username>\.ollama\models
[Service] 下边添加
Environment="OLLAMA_MODELS=你自己路径/models"
# 依次执行下面命令
# 1.刷新配置
sudo systemctl daemon-reload
# 2.重启服务
sudo systemctl restart ollama.service
# 3.查看服务状态
sudo systemctl status ollama
active (running) 说明执行成功
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2025-08-06 16:13:23 CST; 1 day 17h ago
Main PID: 282396 (ollama)
Tasks: 29 (limit: 289442)
Memory: 1.2G
CPU: 2min 32.570s
CGroup: /system.slice/ollama.service
└─282396 /usr/local/bin/ollama serve
8月 07 08:25:22 inspur-NF5468M5 ollama[282396]: llama_context: CUDA_Host compute buffer size = 11.01 MiB
8月 07 08:25:22 inspur-NF5468M5 ollama[282396]: llama_context: graph nodes = 1042
8月 07 08:25:22 inspur-NF5468M5 ollama[282396]: llama_context: graph splits = 2
8月 07 08:25:22 inspur-NF5468M5 ollama[282396]: time=2025-08-07T08:25:22.957+08:00 level=INFO source=server.go:637 msg="llama runner started in 1.26 seconds"
8月 07 08:25:25 inspur-NF5468M5 ollama[282396]: [GIN] 2025/08/07 - 08:25:25 | 200 | 5.540632594s | 172.17.0.5 | POST "/api/chat"
8月 07 08:25:28 inspur-NF5468M5 ollama[282396]: [GIN] 2025/08/07 - 08:25:28 | 200 | 2.438413353s | 172.17.0.5 | POST "/api/chat"
8月 07 08:25:46 inspur-NF5468M5 ollama[282396]: [GIN] 2025/08/07 - 08:25:46 | 200 | 3.831759752s | 172.17.0.5 | POST "/api/chat"
8月 07 08:25:49 inspur-NF5468M5 ollama[282396]: [GIN] 2025/08/07 - 08:25:49 | 200 | 2.713841853s | 172.17.0.5 | POST "/api/chat"
8月 08 09:37:43 inspur-NF5468M5 ollama[282396]: [GIN] 2025/08/08 - 09:37:43 | 200 | 4.482484ms | 192.168.5.161 | GET "/"
8月 08 09:37:43 inspur-NF5468M5 ollama[282396]: [GIN] 2025/08/08 - 09:37:43 | 404 | 7.172µs | 192.168.5.161 | GET "/favicon.ico"
使用 ollama list 查看模型,如果重新更换了位置,模型这里列表应该为空。

# 运行本地模型
为了方便测试,我们运行 DeepSeek 量化模型,只有 1.1G。
什么是量化模型?
模型量化(Model Quantization) 是一种模型压缩和加速技术,旨在减小神经网络模型的存储空间和计算量,同时尽可能保持模型的精度。核心思想是将模型参数(如权重和激活值)从高精度的数据类型(通常是32位浮点数,FP32)转换为低精度的数据类型(如8位整数,INT8,或更低的位数)。
说白了,就是把量化值高精度转为低精度例如:
一个权重值 0.235987654321,在推理中即使保留成 0.236(INT8 对应),对结果影响很小,但计算和存储开销大幅下降。
可以从 ollama 上面查找相应模型
模型查找地址:https://ollama.com/search (opens new window)
下边运行 DeepSeek 模型
ollama run deepseek-r1:1.5b-qwen-distill-q4_K_M

下载模型的过程中,停止了几次再下载发现速度会很快,具体原因不清楚,😜
# 命令参数
以下是 Ollama 使用常见的指令:
ollama serve #启动ollama
ollama create #从模型文件创建模型
ollama show #显示模型信息
ollama run #运行模型 指定模型名称 如: ollama run deepseek-r1:1.5b-qwen-distill-q4_K_M
ollama pull #从注册表中拉取模型
ollama push #将模型推送到注册表
ollama list #列出模型
ollama cp #复制模型
ollama rm #删除模型
ollama help #获取有关任何命令的帮助信息
# 问题
# 1. 如何查看启动日志
sudo journalctl -e -u ollama
# 2.127.0.0.1 可以访问,通过内网 IP 无法访问解决方法
找到 ollama 服务启动配置文件
/etc/systemd/system/ollama.service
[Service] 下边添加
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
重新加载配置及重启服务
systemctl daemon-reload
systemctl restart ollama
如提示没有权限,命令前面添加 sudo
正常访问是以下提示

# 3.启动模型报内存不足
(base) zh@inspur-NF5468M5:~$ ollama run deepseek-r1:1.5b-qwen-distill-q4_K_M
Error: 500 Internal Server Error: llama runner process has terminated: CUDA error: out of memory
current device: 0, in function ggml_backend_cuda_device_get_memory at //ml/backend/ggml/ggml/src/ggml-cuda/ggml-cuda.cu:2917
cudaMemGetInfo(free, total)
//ml/backend/ggml/ggml/src/ggml-cuda/ggml-cuda.cu:77: CUDA error
默认 ollama 使用的 GPU, 查看服务器 GPU 资源是否充足 查询命令 nvidia-smi ,如果 GPU 资源不充足,可以强制 ollama 使用 CPU,不过速度会下降很多。
# 指定显卡启动
CUDA_VISIBLE_DEVICES=1 ollama run qwen3:8b
参考资料
- https://blog.csdn.net/yyh2508298730/article/details/138288553
- https://www.cnblogs.com/taoxiaoxin/p/18491649#%E4%B8%89%E5%91%BD%E4%BB%A4%E5%8F%82%E6%95%B0
- https://www.cnblogs.com/obullxl/p/18295202/NTopic2024071001